logistic�ع�
������ѧ�����쾫�������ǡ�logistic�ع�������������⣡
�����spss��logistic�ع�
����Logistic�ع���Ҫ��Ϊ���࣬һ���������Ϊ�������logistic�ع飬���ֻع��������logistic�ع飬һ���������Ϊ���������logistic�ع飬����������ѡ�����ֲ�Ʒ�����ֻع��������logistic�ع顣����һ���������Ϊ���������logistic�ع飬���粡�صij̶��Ǹߣ��У���ѽ�ȵȣ����ֻع�Ҳ���ۻ�logistic�ع飬�������logistic�ع顣
������ֵlogistic�ع飺
����ѡ����������ع顪����Ԫlogistic��������壬�������ѡ��Ķ�������������û��ʲô���ʣ�Ȼ���±�д��һ��Э��������û�к����ʲô����Э�������ڶ�Ԫlogistic�ع���߿�����ΪЭ�����������Ա��������߾����Ա�����������Ա���ѡ��Э�����Ŀ����ߡ�
����ϸ�ĵ����ѻᷢ�֣���ָ��Э�������Ǹ���ͷ�±ߣ�����һ��СС�İ�ť������a*b�������ť������������ѡ����ġ�����֪������ʱ��������������һ�������µ�ЧӦ����������ͽ������ۺ���һ�𣬻�Խ����̶���һ���µ�Ӱ�죬��ʱ�����Ǿ���Ϊ�����н���ЧӦ����ô����Ϊ��ģ�͵�ȷ���Ͱ��������ЧӦҲѡ��ģ����ȥ���������ұߵ��Ǹ������ѡ�����a����סctrl����ѡ�����b����ô���Ǿ�ͬʱѡס�����������ˣ�Ȼ����Ǹ�a*b�İ�ť��������һ���µ����ֺܳ��ı����ͳ�����Э�����Ŀ�����ˣ��������ǵĽ������õı�����
����Ȼ�����±���һ�������������˵���Ĭ�ϵ��ǽ��룬����ǿ������ѡ��ı��������뵽ģ����ߡ���ȥ���뷨���⣬����������ǰ�����������һ��Ĭ�Ͻ���Ϳ����ˣ������������ģ���б�����pֵ���ϸ��������������������±ߵ�ѡ�������������ѡ����ĸ����ġ�һ��Ҳ���ù�����
����ѡ��������Ժ������ࣨ���Ͻǣ�������Ի���������Ի�����ߣ���ߵ�Э�����Ŀ���������ѡ�õ��Ա������ұ�д�ŷ���Э�����Ŀ�����ǿհġ���Ҫ��Э������ߵ��ַ��ͱ����ͷ������ѡ������Э�������ȥ��ϵͳ���Զ������Ʊ��������������ʲô���Ʊ����������ǰ�ģ���������ַ��ͱ���ָ������ֵ��ǩ��ע���ñ�������Ȼ�����֣�ϵͳҲû�������������ѡ���Ժ���Э�����±���һ�����ĶԱȵĿ������֪�������ڷ��������spss��Ҫ��һ�����գ�ÿ�����ͨ����������ս��бȽ����õ���������ĶԱ��������������ѡ����յġ�Ĭ�ϵĶԱ���ָʾ����Ҳ����ÿ�������������бȽϣ�����ָʾ������м���ֵ�ȡ��������Ǻ���Ҫ��Ĭ�ϾͿ����ˡ�
�������������Ȼ�����Ի���ѡ���ʣ����Ա������Э����������������ѡ��Ի���ѡ����ͼ������ֵ������ԣ�������ʷ��exp��B����CI����ģ���а������������������ÿ�������С�������Э�����������͵ģ�����С�������ǻ�Ҫ��ѡHosmer-Lemeshow��϶ȣ������϶ȱ��ֵĻ�Ϻ�һЩ��
����������ȷ����
����Ȼ�ͻ��������ˡ���Ҫ�������������
������һ������ģ��ϵ���ۺϼ������Ҫ����ģ�͵�pֵ�Dz���С��0.05���ж��������logistic�ع鷽����û�����塣
�����ڶ�����ʾģ�ͻ��ܱ����������������R^2�������������ϵ����Ҳ��αR^2���������������Իع���ľ���ϵ����Ҳ�DZ�ʾ��������ܹ�����ģ�͵İٷ�֮���١����ڼ��㷽����ͬ���������������ϵ����ֵ������һ�������dz��벢����ܴ�
�������±ߵķ�����������ģ�͵��ȶ��ԡ���������һ�аٷֱ�У���±ߵ����������г�����ʵ��ֵΪ0����1ʱ��ģ��Ԥ����ȷ�İٷֱȣ��Լ�ģ���ܵ�Ԥ����ȷ�ʡ�һ����ΪԤ����ȷ���ʴﵽ�ٷ�֮��ʮ�������ã����湻�͵ģ�����Ȼ��ȷ��Խ��Խ�á�
������Ȼ���������Ҫ�ı��ˣ������еı���������һ���Ǹ�B�±���ÿ��������ϵ���������е�pֵ�������ÿ�������Ƿ��ʺ����ڷ���������ij���������ʺϣ��Ǿ�Ҫ����ȥ������������ع顣����������Ϳ���д��logistic�����ˣ�P=Exp(����+a1*����1+a2*����2.������)/(1+Exp(����+a1*����1+a2*����2.������))��������ѧ��һ��ͳ�ƣ��Ǿ�Ӧ�ö������ʽ�ķ��̲�İ�����ṩ��������������������һ������0��1������Ҳ�������ģ�����趨��ֵ�Ƚϴ����������ĸ��ʣ�������������������������0������1Ϊû�������������ģ�����������û�������ĸ��ʡ��������ֱ�Ӽ��������ĸ��ʣ��Ǿ���Ҫ����һ���趨����1ȥ����������
�����������������һ��EXP��B����Ҳ����ORֵ��Ŷ������ɲ��ǻ��ߵ���˼��ORֵ�����Ʊȡ������Իع���������ñ���ϵ�����Ա������Ա��������������Ӱ������ǿ������logistic�ع�������������Ʊ����Ƚϲ�ͬ����������������Ӱ�졣�ٸ����ӡ��������뿴�Ա����ij�ֲ��Ƿ��ת��Ӱ�죬����0����Ů��1�����У�0��������ת��1������ת���������������ORֵΪ2.9����ôҲ����˵���˵ĺ�ת�Ŀ�����Ů�˺�ת��2.9����ע�⣬���ﶼ������ֵ�ϴ���Ǹ����Ϊ���ġ�����ORֵ����ֱ�Ӹ�����������������0,1,2������һ�������ʱ���Ǿ���2��1��2.9����1��0��2.9�����Դ����ơ�ORֵ���ڷ���ûʲô���ף�����������ֱ�۵�����ģ�͡���ʹ��ORֵ��ʱ��һ��Ҫ�����95%�����������������жϡ�
�����������ؾ��������ֱ��ͼ���Ͳ��ٽ����ˡ�
����
����
����
��������logistic�ع飺
����ѡ����������ع顪������logistic��������壬�������Ҷ�֪��ѡʲô��������±���һ���ο����Ĭ�ϵĵ�һ���Ϳ��ԡ���Ȼ�����������������Ӻ�Э�����������ԣ������������Ҫ��ѡ������ģ���ô������ʲô�����أ��ٺ٣���������ڣ�������߷ŵ�������ķ�������������Ա�ְҵʲô�ģ��Լ�����������ʵ������logistic�ع�ʱ���Ա������Ƿ�����������������DZȽ��ٵġ�������Э������߷ŵ��ǵȼ����ϣ����粡������س̶Ȱ������䰡����ʮ��Ϊһ�����������һ��һ���Ļ��Ϳ������������ɻ��ǣ�֮��ġ��ڶ���logistic�ع���ߣ�ϵͳ���Զ������Ʊ����������ڶ���logistic�ع���ߣ���Ҫ�Լ��ֶ������ˡ������ϱߵĽ��ͣ�����֪�����úõ��Ʊ���Ҫ�ŵ������Ǹ������ȥ��
����Ȼ��㿪ģ���Ǹ��Ի����ۣ��ÿֲ���һ���Ի�����֪���Ǹ���ġ��ã�����һ����������ϱ������Ѿ�˵�����������Ǹ�����ˣ���ô�������⣬��ЧӦ���DZ���������ģ�͵�Ӱ�졣��ȷ����һ���Ժ�����Ի����û����ô��ѡ�ˡ�ָ��ģ����һ��������ģ�ͣ���ЧӦָ����ֻ���Ա�����������ķ��̣���������ͨ�����֡�ȫ����ָ���ǰ�����������ЧӦ���������Ӻ����ӵĽ���ЧӦ��ģ�ͣ���Ҳ������Ϊʲôֻ��ȫ���ӣ�û��ȫЭ���������������ĺ��ѣ����Ա���չ�����������������趨/����ʽ��������Լ��ֶ����ý��������ЧӦ��ģ����һ����������������ǿ������Ļ�������ġ��������Ͳ����ن����˰ɰ���
���������������ͳ�����Ի���ѡ��������ժҪ��αR��������ժҪ��ģ����϶���Ϣ����Ԫ������ԣ����������϶ȣ����ƣ���Ȼ�ȼ��飬��������������ȫ������������ѡ���ѡΪ�ּ�ǿ����Ŀ���Ƴ���Ŀ�����棬��ѡ����Э�������ȷ��������ѡ���ˣ���
��������Ͷ���logistic�ع��࣬���Ƕ���һ����Ȼ�ȼ��飬pֵС��0.05��Ϊ���������塣Ȼ������ֱ�ӿ��������Ʊ����������ǵ��������n���࣬�Dz������Ʊ������n-1��Ľؾ࣬����1������2������������Zm����Exp������m+am1*����1+am2*����2+������������ô���е�m����������ĸ���ΪZn/1+Z2+Z3+����+Zn(��������Ե�һ��Ϊ�ο����Ļ������ǾͲ����й��ڵ�һ��IJ�������ô��һ�����Ĭ�ϵ�1��Ҳ����˵Z1Ϊ1)��
����
��������ع飨�ۻ�logistic�ع飩��
����ѡ��˵����������ع顪����������塣����������ӣ�Э�������ѡȡ�Ͳ����ظ��ˡ�ѡ��Ի���Ĭ�ϡ�������Ի���ѡ��϶�ͳ�ƣ�ժҪͳ�ƣ��������ƣ�ƽ�����飬������Ӧ���ʣ�ʵ�������ʣ�ȷ����λ�öԻ�������ĵ�ģ�ͶԻ������ƣ�Ҳ���ظ��ˡ�ȷ����
�������������е�һ������ƽ����������������pֵС��0.05����Ϊб��ϵ�����ڲ�ͬ������Dz�һ���ġ�����������Ʊ��ó��IJ���Ҳ������ͬ���������ǵ���������ĸ�ˮƽ���Ա�������������ô�������Ʊ������������ֵa1,a2��a3��Ҳ���ǽؾࣩ�������Ա����IJ���m��n�����㷽��ʱ������������Linkֵ��Link1=a1+m*x1+n*x2��Link2=a2+m*x1+n*x2��Link3=a3+m*x1+n*x2�������нؾͬ������linkֵ�Ժ�p1=1/(1+exp(link1)),p1+p2=1/(1+exp��link2��),p1+p2+p3=1/(1+exp(link3)),p1+p2+p3+p4=1..
����ͨ���ϱߵ��⼸�����̾��ܼ�������Եĸ����ˡ�
����
����Logistic�ع鵽����������Ѿ������ˡ����һ��Ҫ���칫ʽ��Ū��ɾ�����ˡ�ϣ���ܶ������������ϡ�
��Ԫ�ع������logistic�ع�ķ������������ϵ
1�����ͬ��
��1���������Իع�ģ�Ϳ���Ϊ��ֱ��ģ�͵�ֱ���ƹ㣬�������������������Ա���������ģ�ͼ�Ϊ�������Իع�ģ�͡�
��2��logistic���ڸ����ͷ����Իع飬���о�������(����չ�������)�۲�����һЩӰ������֮���ϵ��һ�ֶ��������������
2���������ص�
��Ԫ�ع������Ӧ������1������ֵ��������̬�ֲ�)���Ա�����2����2�����ϣ��������ֵ������Ҳ���������������������������
logistic�ع�ķ���Ӧ������1�������� �����������ֲ��������� /��������������Ա�����2����2�����ϣ���ֵ���������������������/�������������
����ع�ģ��LogitP=(����)ƫ�ع�ϵ�������ʾ�ڿ����������ػ�˵�۳��������ص����ú�(���������Ա����̶�����������)��ijһ���Ա����仯һ����λʱ���������Y�仯��ƽ����С��
��ʾ�ڿ����������ػ�˵�۳��������ص����ú�(���������Ա����̶�����������)��ijһ���ظı�һ����λʱ��ЧӦָ�귢���벻�����¼��ĸ���֮�ȵĶ����仯ֵ(logitP��ƽ���仯��)����lnOR��
3����������LINE��
1��L�����ԡ����Ա���X��Ӧ����Y֮��������Թ�ϵ��
2��I�������ԡ���Yֵ���������ģ������Ҫ��в������������������أ�
3��N����̬�ԡ�����������вe���Ӿ�ֵΪ�㣬����Ϊ 2����̬�ֲ���
4��E���ȷ�����������е��Ա���X���в�e�ķ����롣
�۲����case��֮���������������ֵ������Ӧ�ӽ���̬�ֲ�����������ƫ����̬�ֲ�����������������Ӷ���ֲ���Ҫ���㹻����������LogitP���Ա��������Թ�ϵ��
�����spss����logistic�����ػع����
1����spssͳ��������Ȼ����Analyze - Regression - Binary Logistic����
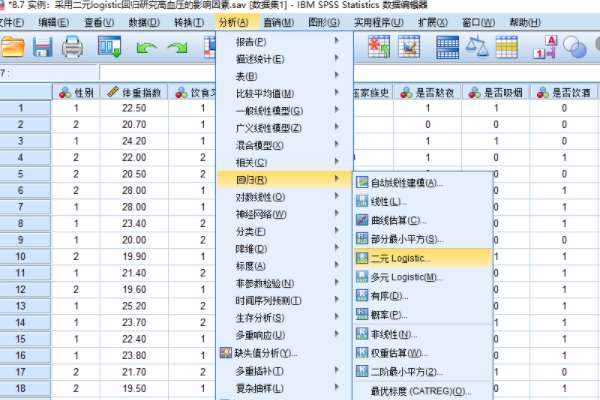
2�����֡����ع顱���ڡ�������Ѫѹ�����롰�������������������������硰�Ա𡱺͡�����ָ���������롰�ָ��������С�
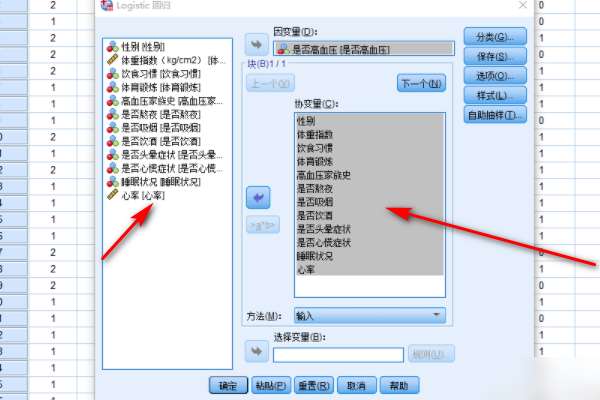
3�����������ࡱ������������Ա��������Ҳ�ġ�����Э���������С�����������£��Ա������Ա𡱣�����ʳϰ�ߣ������������Ƿ�����������Ҳ�Ŀ���ѡ������� ���ο����ѡ�����һ�����˴�ѡ��Ĭ�ϵġ�����������������
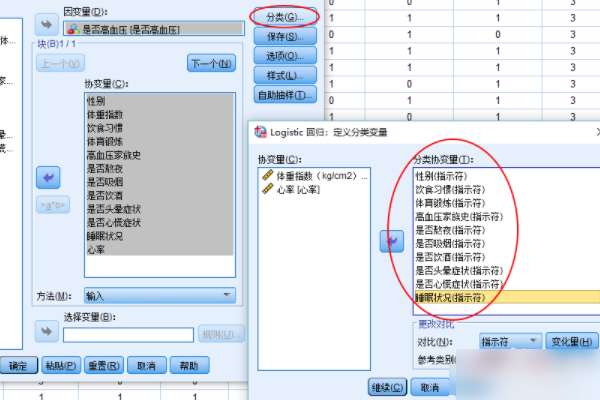
4�����������桱��ѡ�С����ʡ��������Ա����Ȼ��������
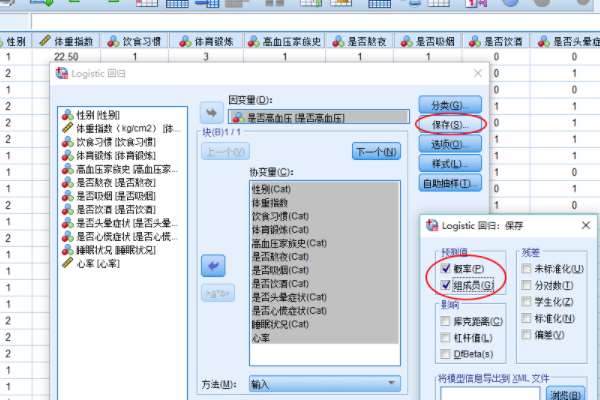
5�������ѡ�����ѡ��Hosmer-Lymeshaw Fitting Goodness���͡�95��Confidence Interval����Ȼ������Continue����
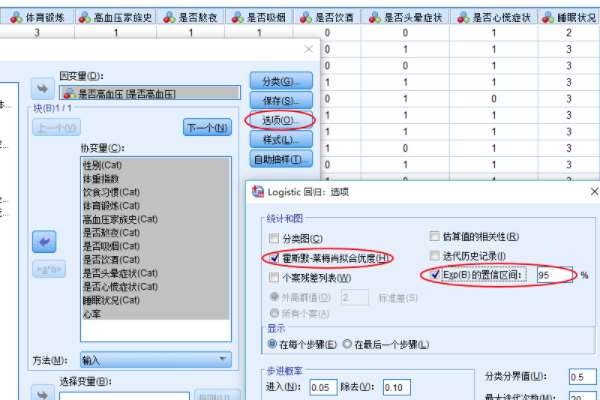
6��������ѡ�����롰���ȷ������
logistic�ع��Dz���Ҫ���Ա���������̬�ֲ�����
û�����Ҫ��
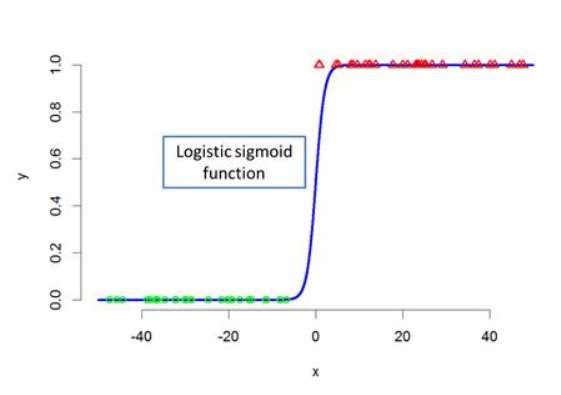
logistic�ع�ֻҪ���Ա�����Logistic���������Թ�ϵ��
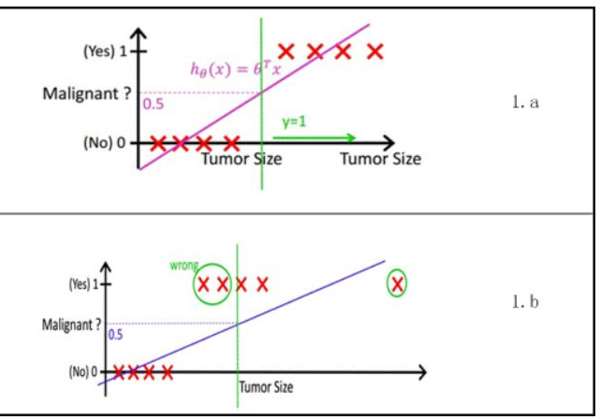
Logistic�ع�ʵ���Ƿ������ʳ���û�з���������ȡ���������������̫�����ı任�ı���ȡֵ�����ì�ܺ�������Ա���������߹�ϵ������ԭ���Ƿ�����δ�����ĸ��ʳ�Ϊ�˱�ֵ �������ֵ����һ�����壬��ȡֵ��Χ�����ٽ��ж����任������������ı䡣
������ˣ����ֱ任����ʹ����������Ա���֮������Թ�ϵ�����Ǹ��ݴ���ʵ�����ܽᡣ���ԣ�Logistic�ع�Ӹ����Ͻ�������Ҫ��������������ô������⡣���У�LogisticӦ�ù㷺��ԭ����������ʵ���������ģ���Ǻϡ�����һ�������Ƿ�����������ֵ���Ա����Ĺ�ϵ��
��չ���ϣ�
��Ҫ��;
1��Ѱ��Σ������
����������˵��Ѱ��ijһ������Σ�����صȡ�
2��Ԥ��
����Ѿ�������logistic�ع�ģ�ͣ�����Ը���ģ�ͣ�Ԥ���ڲ�ͬ���Ա�������£�����ij����ij������ĸ����ж��
3���б�
ʵ���ϸ�Ԥ����Щ���ƣ�Ҳ�Ǹ���logisticģ�ͣ��ж�ij������ij��������ij������ĸ����ж��Ҳ���ǿ�һ��������ж��Ŀ�����������ij����
����logistic�ع���õ�������;��ʵ���е�logistic�ع���;�Ǽ�Ϊ�㷺�ģ�logistic�ع鼸���Ѿ��������в�ѧ��ҽѧ����õķ�����������Ϊ����������Իع�����кܶ�����ƣ��Ժ��Ը÷���������ϸ�IJ�����ʵ�����кܶ������������ֻ����Logistic�ع�����ɹ�Ҳ��Ӧ�����ġ�
�ο�������Դ���ٶȰٿ�-logistic�ع�
probit�ع���logistic�ع���ʲô����
probit��logistic������Ϊ����˼��ͬ���÷���ͬ�����ص㲻ͬ��
һ����˼��ͬ
1��probit�����ʵ�λ��
2��logistic�����������ţ�����
�����÷���ͬ
1��probit��
probitģ�ͷ�����̬�ֲ�������ģ�Ͷ�����ɢѡ��ģ�͵ij���ģ�͡���logitģ�ͼ�ֱ�ӣ�Ӧ�ø��㡣���ң�����������������ʱ��Logit��Probitû�б��ʵ�����һ������¿��Ի��á��������ڲ��õķֲ�������ͬ��ǰ��������������������ʷֲ������������������������̬�ֲ���

2��logistic��Logitģ�����������ɢѡ��ģ�ͣ�Ҳ��ĿǰӦ������ģ�͡�Logitģ����Luce��1959������IIA�����״ε����ģ�Marschark��1960��֤����Logitģ�������Ч�����۵�һ���ԣ�Marley��1965���о���ģ�͵���ʽ��Ч�÷�ȷ����ķֲ�֮��Ĺ�ϵ��
�������ص㲻ͬ
1��probit�����ݳ�̬Ƶ�ʷ���ƽ������ƫ�����ͳ�Ƶ�λ��
2��logistic����ɢѡ��ģ��֮һ��Logitģ�����������ɢѡ��ģ�͡�
Logistic�ع����ָ����Ҫ�̶ȵ���Ҫ������ʲô��
Logistic�ع飺ʵ���������б��������ӵ�кܲ���б�Ч�ʶ������á�
1�� Ӧ�÷�Χ��
�� ���������в�ѧ���ϵ�Σ�����ط���
�� ʵ������ҩ��ļ���-��Ӧ��ϵ
�� �ٴ���������
�� ������Ԥ�����ط���
2�� Logistic�ع�ķ��ࣺ
�� ����������������ͷ֣�
������
�����
���ж��ֽ�Ϊ����
�� ���о������֣�
�� ��Logistic�ع�
������Logistic�ع�
������Ե��������Ͳ�һ����������Գ����о���ǰ�������Ի������о���
3��Logistic�ع��Ӧ�������ǣ�
�� �����ԡ����۲�������������ģ�
�� LogitP���Ա��������Թ�ϵ��
�� ������������ֵ�Dz������ո�50�����ϻ�Ϊ�Ա�����5-10������10��Ϊ�ˣ�����������ͳ�Ƽ����������ķ�չ����������С���ܽ�����Ȼ���Ƶ�����¿ɲ��þ�ȷlogistic�ع��������ʱҪ�������������̫�࣬�ұ��������̫�ࣻ
�� ���������Ͻ���logistic�ع����ʱ���۲�ʱ��Ӧ����ͬ�������迼�ǹ۲�ʱ���Ӱ�죨������Poisson�ع飩��
4�� ���logistic�ع鷽�̵IJ��裺
�� ��ÿһ���������������������е����ط�����
�� ���ݵ���ɢ�������������Ա����ڷ��������г�����Ҫ������ɢ��ɵȼ����ϡ��ɲ��õķ��������ݾ��������ɢ�����ǰ����ķ֡����λ������ȷ���ȼ���Ҳ�ɲ��þ�������������Ͼ�Ϊ�������࣬��Ϊ��ɢ������
�� �����������һЩ�Ա������в��ֶ����ط�������̽�ָ��Ա������ȼ���������ֵ����������ģ��ʱ�����˳߶ȣ������Ա������б�Ҫ�ı����任��
�� �ڵ���������������Ա��������Ļ����ϣ���P�ܦ�����ȡ0.2��0.15��0.3���ı������Լ�רҵ����Ϊ��Ҫ�ı������ж����ص���ɸѡ��ģ�ͳ���ÿ���һ��ģ�ͽ��������ָ��ֵ�����û��ж�ģ�����Ӻ�ɸѡ���������Բ���˫��ɸѡ������a���������ɸѡ��scoreͳ������Gͳ������LRS(��Ȼ��ͳ����)���û�ȷ��Pֵ�ٽ�ֵ�磺0.05��0.1��0.2��ѡ��ͳ�������������ı�������ģ�ͣ�b��������ѡ����Zͳ����(Waldͳ����)���û�ȷ����Pֵ������ˮƽ�������������ߣ���ģ������������������ѡ���������ѭ����ֱ���ޱ���ѡ�룬Ҳ�ޱ���ɾ��Ϊֹ��ѡ�������������ֵ��ȷ��Ҫ�����������ͱ����Ķ�Ѷ�����һ��أ�������ģ�͵ı���ƫ�࣬�����ѡ���ֵ����������֮����ѡ���ֵ�����ɾ��������ɸѡ���IJ�ͬ��Ӱ�������������������˽���Ƚ�ʱӦ��ע�⡣
�� �ڶ�����ɸѡģ�͵Ļ����ϣ��������ޱ�Ҫ��������Ľ����������������Ľ�������Ϊһ���������ã����ƹ㵽������༶�������ã�����ʵ��Ӧ���У���������������(Ҳ��ģ�ͱ�����Ҫ��)�������о��������ã�������о�������һ���������á�
�� ��רҵ����Ϊ��Ҫ��δѡ��ع鷽�̵�Ҫ����ԭ��
5�� �ع鷽��������ӵ��жϣ�Ϊ���Իع鷽���ж����ݣ�������logistic�ع������
�� ����ϵ��(R2)��У������ϵ��( )�������������ۻع鷽�̵����ӡ�R2�����Ա������������Ӷ����ӣ�������ҪУ����У������ϵ��( )Խ����Խ�š��������о�ָ��R2�Ƕ�Ԫ���Իع��о����õ���һ��ָ�꣬��ʾ����������ı䶯����ģ�����Ա��������͵İٷֱȣ������漰Ԥ��ֵ��۲�ֵ֮��������⣬�����logistic�ع��в��ʺϡ�
�� Cpѡ��ѡ��Cp��ӽ�p��p��1�ķ��̣���ͬѧ�߽��Ͳ�ͬ����Cp����SPSSֱ�Ӽ��㣬������Ҫ�ֹ���1964��CL Mallows�����
Cp�ӽ���p+1����ģ��Ϊ��ѣ�����pΪ�������Ա����ĸ�����mΪ�Ա����ܸ�����
�� AIC��1973�����ձ�ѧ�߳�����AIC������AICԽС��ϵķ���Խ�á�
��logistic�ع��У�����ģ������Ŷȵ�ָ����Ҫ��Pearson ��2��ƫ��(deviance)��Hosmer- Lemeshow (HL)ָ�ꡢAkaike��Ϣ��(AIC)��SCָ��ȡ�Pearson ��2��ƫ��(deviance)��Ҫ�����Ա���������Ϊ�����������������Ա��������Һ��������ͱ���ʱ����HLָ�����Ϊǡ����Pearson ��2��ƫ��(deviance)��Hosmer- Lemeshow (HL)ָ��ֵ�����Ӧ�2�ֲ�����2������ͳ��ѧ����(P>0.05)��ʾģ����ϵĽϺã���2������ͳ��ѧ����(P��0.05)���ʾģ����ϵĽϲAIC��SCָ�껹�����ڱȽ�ģ�͵����ӣ�����϶��ģ��ʱ�����Խ���ͬģ�Ͱ���AIC��SCָ��ֵ����AIC��SCֵ��С��һ����Ϊ��ϵø��á�
6�� ��Ϸ��̵�ע�����
�� ���з�����϶��Ա���ɸѡ������ѡ��[ǰ������forward�������˷���backward�����ع鷨��stepwise��]ʱ����������ļ���ˮҪС�ڻ�����������ļ���ˮ��
�� С��������ˮ����Ϊ0.10��0.15���������Ѧ���Ϊ0.05��ֵԽС˵���Ա���ѡȡ�ı�Խ�ϣ�
�� ���ع��ʱ�ɸ�����Ҫ�ſ������ƽ��뷽�̵ı�����Ӳ�Խ������Ȥ���о�����ѡ�뷽�̣�
�� ǿӰ����¼��ѡ�������Ͻ���ÿһ��������Իع�ģ�͵�Ӱ��Ӧ����ͬ�ȵģ�ʵ�ʲ�����ˡ���Щ�����㣨��¼���Իع�ģ��Ӱ��ܴ��ɹ�ʧ�������ɵĵ�Ӧɾȥ��û�д����ǿӰ�����ܺ��Ա�����Ӧ����������йأ���������ɾ����
�� ���ع����Ե���ϣ�SPSS�е�ָ�꣩��a�����ȣ�Խ������0��������Խǿ��b��������Խ������0��������Խǿ��c����ָ����Խ������Խǿ��
�� �쳣��ļ�飺��Ҫ���������(outher)���߸ܸ˵�(high leverage points)�Լ�ǿӰ���(influential points)���������ָ�в�����������ö�ĵ㣻�߸ܸ˵���ָ����������Ʒ��Զ�ĵ㣻ǿӰ�����ָ��ģ���нϴ�Ӱ��ĵ㣬ģ���а����õ��벻�����õ��ʹ��õĻع�ϵ�����ܴ�����������߸ܸ˵㲻һ����Ӱ��ع�ϵ���Ĺ��ƣ������������������Ǹ߸ܸ˵���ܿ�����һ��Ӱ��ع鷽�̵ġ��к����㡣������㡢�߸ܸ˵㡢ǿӰ�����ϵ�ָ����Pearson�вDeviance�в�ܸ˶�ͳ����H��hat matrix diagnosis����Cook ���롢DFBETA��Score����ͳ�����ȡ������ָ���У�Pearson�вDeviance�в�������������㣬���ij�۲�ֵ�IJв�ֵ>2�������Ϊ��һ������㡣�ܸ˶�ͳ����H���������ָ߸ܸ˵㣬 Hֵ�����Ʒ˵������������Ʒ��Զ������Ϊ��һ���߸ܸ˵㡣Cook ���롢DFBETAָ�����������������߸ܸ˵�Իع�ģ�͵�Ӱ��̶ȡ�Cook�����DZ����в�ܸ˶����ߵĺϳ�ָ�꣬��ֵԽ��������Ӧ�Ĺ۲�ֵ��Ӱ��Խ��DFBETAָ��ֵ��ӳ��ij����Ʒ��ɾ����logistic�ع�ϵ���ı仯���仯Խ��(��DFBETAָ��ֵԽ��)�������ù۲�ֵ��Ӱ��Խ�����ģ���м���������㡢�߸ܸ˵��ǿӰ��㣬����Ӧ����רҵ֪ʶ�������ռ�����������������ԭ������鴦���������Բ������¼����Ӧ����У���������þͱ��������̬�ȣ������Ƿ�����µ�ģ�ͣ�������ֻ�Ǽ�ɾ���������¡���Ϊ�����ೡ�ϣ��쳣��ij���ǡ��������̽��ijЩ���Ȳ�����Ļ�����Ϊ��Ҫ���ص�������
7�� �ع�ϵ�����ŷ�������Ҫ����ѡ�������̵�ԭ��
�� ���ڶ�Ԫ�����ԣ�
�� ����ҪӰ�������δ�������ڣ�
�� ijЩ���������IJ���ܴ�
�� ������ͻ��������������
�� �����ı仯��Χ��С��
�� ������̫�١�
8�� ��������
�� Logistic�ع��еij����b0����ʾ���ڲ��Ӵ��κ�DZ��Σ�գ��������������£�ЧӦָ�귢���벻�����¼��ĸ���֮�ȵĶ���ֵ��
�� Logistic�ع��еĻع�ϵ����bi����ʾ�����������Ա����̶����䣬ijһ���ظı�һ����λʱ��ЧӦָ�귢���벻�����¼��ĸ���֮�ȵĶ����仯ֵ����OR��RR�Ķ���ֵ����Ҫָ�����ǣ��ع�ϵ���µĴ�С������ӳ�����Լ�����������Ҫ�ԣ���ô�������ض�ģ��������뼲��
��չ��
��ϵ��ǿ��? (InL(t-1)-InL(t))���ַ����������һ�¡�
�� �������ؼ佻������ʱ��Logistic�ع�ϵ���Ľ��ͱ�ø�Ϊ���ӣ�Ӧ�ر�С�ġ�
�� ģ���Ƴ�OR���������ʽϵ�ʱ��OR��RR����˷����ʸߵļ������ϲ��ʺ�ʹ�ø�ģ�͡����⣬Logisticģ�Ͳ�����������о��е�ʱ����Ϣ�������Ƿ���ʱ���ϵIJ��죬���ֻ��������ڽ϶̵����ϣ�������������ڵ��ӳ����ع�ϵ����ò��ȶ����������ӡ�
9�� ͳ������
�ܹ�����logistic�ع�����������dz��࣬���õ���SPSS��SAS��Stata��EGRET (Epidemiological Graphics Estimation and Testing Package)�ȡ�
����spss20.0 logistic�ع��������
��֪������IJ������裬�ֱ���Ҫ�����ļ������飬������鲻�ϸ���ô���ͣ��Ŀ�����ĸ�����...
��֪������IJ������裬�ֱ���Ҫ�����ļ������飬������鲻�ϸ���ô���ͣ��Ŀ�����ĸ�����
SPss��logistic�ع齻������
�����ٶ�����Խ������õĻش𣬺ܳ�ݣ��и�����������㡣��SPSSlogistic�ع��У���Ҫ����A��B�������صĽ������ã���ˣ����Ұ�A��Bͬʱѡ�У��㡰a*b������covariates���ǻ���Ҫ��...
�����ٶ�����Խ������õĻش𣬺ܳ�ݣ��и�����������㡣��SPSS logistic�ع��У���Ҫ����A��B �������صĽ������ã���ˣ����Ұ�A��B ͬʱѡ�У��㡰a*b������covariates���ǻ���Ҫ��A��B ��������covariates�� չ��
��A��B ͬʱѡ�У��㡰a*b������covariates��Ϳ��Եõ�A��B �Ľ������ý���ˣ��������Ƿ�A��B ��������covariates����������������¶��ὫA��B ���������Ա�ֱ�A��B�ĵ���ЧӦ���������û�Ҫ����������Categorical��ť����A��B ѡ�룬��������������Ľ���������ؿ�����������õĽ����
������չ����
��չ
лл��Ļش𣬶��Һ��а������Ұ������˵����A��B��A*B������covariates������ó���
A���أ���=0.508��p=0.002��OR(95%)=1.66(1.21-2.28)
B���أ���=0.326��p=0.005��OR(95%)=1.39(1.10-1.74)
A*B��������= -0.641��p=0.013��OR(95%)=0.53(0.32-0.87)
Ϊʲô������A��B ����Σ������(OR>1)������֮��ͱ���˱��������أ�OR<1����
����
�����������������ÿ��Գ������������ã�Ҳ���Գ��ָ��������á��Ӽ��ٷ���������Ƕȣ���Ľ���dz����˸��������á���Ҫע����ǣ�ͳ��ģ�ͽ�����ʾ�㸺�������ÿ����ԵĴ��ڣ��㻹��Ҫ���רҵ֪ʶ��̽�����ֿ������Ƿ��п��ܴ��ڣ������ϵ�Ľ������ܽ�������ͳ��ģ�ͣ�������Ҫ����רҵ֪ʶ��
��չ
лл��Ļش��һ���һ������������㡣���ڷ���A�����ͶԼ�����Ӱ��ʱ������������������Ⱥ�У�A�����;�ΪΣ�����أ�ORֵ�ֱ�Ϊ��1.98��1.27������BMI��Ӱ�켲����һ�����أ��������BMI25Ϊ������˷ֲ���������������������Ⱥ�У�A��������BMI>25��Ⱥ���о������壨P>0.05��������BMI<25��Ⱥ���о�ΪΣ�����أ�����ORֵ���Ƚϴ�(3.58 vs1.65)��Ϊʲô�������ô��IJ���أ�лл��
����
�����������п���˵��BMI>25��Ⱥ����Я��A�����ͶԼ�����Ӱ�첻��A�����п���ֻ��BMI<25��Ⱥ��ΪΣ�����ء���ġ�ORֵ���Ƚϴ�(3.58 vs1.65)��û��˵����Ǹ�ֵ����˭�������жϡ������������ṩ��ORֵ��������ֵ��������п��ܱ����뼲������ϵǿ�Ȳ����ʹ���PֵС��0.05���������ڴ�������ʱ������ˣ�������ж��ǻ�������ȷʹ����ORֵ��ORֵֻӦ���ڲ��������о������ҷ����ʲ��ܸ���10%����ʱORֵ���Խ���RRֵ�����ý����������塣����Ƕ����о���Ӧ��ʹ��RRֵ�����⣬��Ҫ��������������һ��Խ������Ҳʮ����Ҫ��
���ԣ������õ��Ļش�
SPSS �����ط�����logistic�ع���� �е�SE ��B ��...
���Ѿ�֪��OR��95%CI�DZ�ֵ�Ⱥ�95%�����������˼����ô�����Ǽ�����ʲô��˼��������ͣ�������ͬ����ֵ��ʲô��˼����ô���...
���Ѿ�֪��OR ��95%CI�DZ�ֵ�Ⱥ�95%�����������˼����ô�����Ǽ�����ʲô��˼��������ͣ�������ͬ����ֵ��ʲô��˼����ô���
SPSS�����ط�����logistic�ع�����У�SE��ʾ����B��ʾ�ع�ϵ����R��ʾ����Ŷ�ָ�ꡢP��ʾ��P>1��Σ�����ء�P<1�������ء�P=1�����ز������á�
1��SPSS�����ط�����logistic�ع�����ǽ��2012����ģ����a�����Ҫ���ߣ�spss�dz��õĶ����ط���������ͨ��������ˮƽ���������ضԱ�����Ӱ�졣
2����ÿ���Ա��������������أ����Ƿ������Թ�ϵ����������Ա������з���������SPSS�����ط�����logistic�����Ա������������������ǵ÷֣��Ա�����Ҫ���±��룬��Ҫ�ȱ��������������������������ڱ�������һ����
��չ���ϣ�
SPSS�����ط�����logistic�ع�������ܣ�
SPSS�����ط�����logistic����ijһ�ض�����������ڲ��ĸ�Ҫ�غ����е��������ﶼ������������ϵ�����ǿ���������ϵ��֮ΪӰ�죬����Щ����������ϵ�����Ҫ�س�֮Ϊ���� ���ɴ˱�������һ�ַ�������ķ��������ط�������
�ο�������Դ��
�ٶȰٿ�-SPSS
�ٶȰٿ�-�����ط�����
�ٶȰٿ�-logistic�ع�
��������
 ���»������Ĵ�������������Ŀ������Ը���� �����̴�Υ��ˮ�������ر��� ��̨��ý�屨����������7��1�շ���̨������ɽ���������ص�ʱ����Ϊ��С�Ĵ���ˮ���������ز����3000Ԫ̨�� ����̨��ý��ѯ�ʻ���������...[����]���ࣺ֪ʶ��ʱ�䣺12:37
���»������Ĵ�������������Ŀ������Ը���� �����̴�Υ��ˮ�������ر��� ��̨��ý�屨����������7��1�շ���̨������ɽ���������ص�ʱ����Ϊ��С�Ĵ���ˮ���������ز����3000Ԫ̨�� ����̨��ý��ѯ�ʻ���������...[����]���ࣺ֪ʶ��ʱ�䣺12:37 led�ͽ��ܵ��ĸ���
led�ͽ��ܵ��ĸ��� ����������������ѿ�ͬѧ�Ŀκ���ϰ�⣬��Ҫ�ǹ���led�ͽ��ܵ��ĸ�����ָ����ʦΪ����ʦ��LED���ܵ��Ǽ̽�����ӫ���(����ͨ���ܵ�...
[����]���ࣺ֪ʶ��ʱ�䣺14:47 ��������˰˰��
��������˰˰�� ���������������ֵϾͬѧ�Ŀκ���ϰ�⣬��Ҫ�ǹ�����������˰˰����ָ����ʦΪ����ʦ��
��Ŀ����������˰˰��
�⣺<...[����]���ࣺ֪ʶ��ʱ�䣺14:51 ��˰���㷽��
��˰���㷽�� ���������������Ե��ͬѧ�Ŀκ���ϰ�⣬��Ҫ�ǹ�����˰���㷽����ָ����ʦΪ����ʦ��������˰�ƶȵ������˰���ų�̨�˸�������Ⱥ...
[����]���ࣺ֪ʶ��ʱ�䣺14:51 ����������� �����̴�Υ��ˮ�������ر��� ��̨��ý�屨����������7��1�շ���̨������ɽ���������ص�ʱ����Ϊ��С�Ĵ���ˮ���������ز����3000Ԫ̨�� ����̨��ý��ѯ�ʻ���������...[����]���ࣺ֪ʶ��ʱ�䣺12:37
����������� �����̴�Υ��ˮ�������ر��� ��̨��ý�屨����������7��1�շ���̨������ɽ���������ص�ʱ����Ϊ��С�Ĵ���ˮ���������ز����3000Ԫ̨�� ����̨��ý��ѯ�ʻ���������...[����]���ࣺ֪ʶ��ʱ�䣺12:37 ʲô������������
ʲô������������ ������������ǹ��ÿ�ͬѧ�Ŀκ���ϰ�⣬��Ҫ�ǹ���ʲô��������������ָ����ʦΪ����ʦ������������ݹ���˼������������������...
[����]���ࣺ֪ʶ��ʱ�䣺14:58 ʲô����������
ʲô���������� �������������������ͬѧ�Ŀκ�������ϰ�⣬��Ҫ�ǹ���ʲô������������ָ����ʦΪ����ʦ��
��Ŀ��ʲô����������
...[����]���ࣺ֪ʶ��ʱ�䣺14:58 Ȥͷ���뽭�����Ӵ��ս�Ժ��� �����̴�Υ��ˮ�������ر��� ��̨��ý�屨����������7��1�շ���̨������ɽ���������ص�ʱ����Ϊ��С�Ĵ���ˮ���������ز����3000Ԫ̨�� ����̨��ý��ѯ�ʻ���������...[����]���ࣺ֪ʶ��ʱ�䣺12:37
Ȥͷ���뽭�����Ӵ��ս�Ժ��� �����̴�Υ��ˮ�������ر��� ��̨��ý�屨����������7��1�շ���̨������ɽ���������ص�ʱ����Ϊ��С�Ĵ���ˮ���������ز����3000Ԫ̨�� ����̨��ý��ѯ�ʻ���������...[����]���ࣺ֪ʶ��ʱ�䣺12:37 ������ô��
������ô�� ������������ǴӸٴ�ͬѧ�Ŀκ���ϰ�⣬��Ҫ�ǹ���������ô����ָ����ʦΪ���ʦ���������ʱ�ʾһ��ʱ������Ϣ���뱾��ı��ʣ�ͨ...
[����]���ࣺ֪ʶ��ʱ�䣺14:58 ��������
�������� �������������ɽ�̲�ͬѧ�Ŀκ���ϰ�⣬��Ҫ�ǹ�������������ָ����ʦΪ̸��ʦ��
��Ŀ����������
�⣺ ...[����]���ࣺ֪ʶ��ʱ�䣺14:56 ����˹
����˹ �������������������ͬѧ�Ŀκ�������ϰ�⣬��Ҫ�ǹ�������˹��ָ����ʦΪ����ʦ��
��Ŀ������˹
�⣺ ...[����]���ࣺ֪ʶ��ʱ�䣺14:54 ����
���� ����������������ƶ�ͬѧ�Ŀκ���ϰ�⣬��Ҫ�ǹ���������ָ����ʦΪ����ʦ����ʱ�Բ�������˰�շ���������ȷ��ʱ����˰����...
[����]���ࣺ֪ʶ��ʱ�䣺14:53 ƽ����
ƽ���� �������������������ͬѧ�Ŀκ���ϰ�⣬��Ҫ�ǹ���ƽ������ָ����ʦΪ����ʦ��ƽ����Ϊ��װ���ߵ���Ҫ��ɲ��֣������ڱ��ֱ�����...
[����]���ࣺ֪ʶ��ʱ�䣺14:54 ����ͼ��
����ͼ�� ������������Ǽ���λͬѧ�Ŀκ�������ϰ�⣬��Ҫ�ǹ�������ͼ����ָ����ʦΪ����ʦ�����½���ͳ����ͼ������2009���½���ѧ������...
[����]���ࣺ֪ʶ��ʱ�䣺14:54 �ɷַ���
�ɷַ��� ����������������ػ�ͬѧ�Ŀκ���ϰ�⣬��Ҫ�ǹ����ɷַ�����ָ����ʦΪ����ʦ��
��Ŀ���ɷַ���
�⣺ ...[����]���ࣺ֪ʶ��ʱ�䣺14:56 ���֮��
���֮�� �������������·��Ҵͬѧ�Ŀκ�������ϰ�⣬��Ҫ�ǹ������֮����ָ����ʦΪ����ʦ��
��Ŀ�����֮��
�⣺<...[����]���ࣺ֪ʶ��ʱ�䣺14:54 ���洬ԭ��
���洬ԭ�� �������������ϯ����ͬѧ�Ŀκ���ϰ�⣬��Ҫ�ǹ������洬ԭ����ָ����ʦΪë��ʦ��ͨ�繤�����ͷ硢�ŷ硢���������������Լ�����...
[����]���ࣺ֪ʶ��ʱ�䣺14:54 ����
���� ���������������ɸ��ͬѧ�Ŀκ���ϰ�⣬��Ҫ�ǹ���������ָ����ʦΪǮ��ʦ��
��Ŀ������
�⣺ ...[����]���ࣺ֪ʶ��ʱ�䣺14:56 38������
38������ ֪ʶ�㣺��38�������� �ռ�������ù �༭����
[����]���ࣺ֪ʶ��ʱ�䣺10:57
��֪ʶ�������1��38�������ڵ�Ƭ��ϵͳ�е�������ʲô? 2����vh... aidma
aidma ֪ʶ�㣺��aidma�� �ռ����ᳬ�� �༭�����ӻ�Ů��
[����]���ࣺ֪ʶ��ʱ�䣺12:08
��֪ʶ�������1��SOV/SOM��ʲô��AIDMA��AIDAS���۴���ʲô...