python爬虫实例
曲谱自学网今天精心准备的是《python爬虫实例》,下面是详解!
python网络爬虫可以干啥
世界上80%的爬虫是基于Python开发的,学好爬虫技能,可为后续的大数据分析、挖掘、机器学习等提供重要的数据源。
什么是爬虫?
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
其实通俗的讲就是通过程序去获取web页面上自己想要的数据,也就是自动抓取数据
爬虫可以做什么?
你可以用爬虫爬图片,爬取视频等等你想要爬取的数据,只要你能通过浏览器访问的数据都可以通过爬虫获取。
爬虫的本质是什么?
模拟浏览器打开网页,获取网页中我们想要的那部分数据
浏览器打开网页的过程:
当你在浏览器中输入地址后,经过DNS服务器找到服务器主机,向服务器发送一个请求,服务器经过解析后发送给用户浏览器结果,包括html,js,css等文件内容,浏览器解析出来最后呈现给用户在浏览器上看到的结果
所以用户看到的浏览器的结果就是由HTML代码构成的,我们爬虫就是为了获取这些内容,通过分析和过滤html代码,从中获取我们想要资源。
python新手关于爬虫的简单例子
以下代码调试通过:
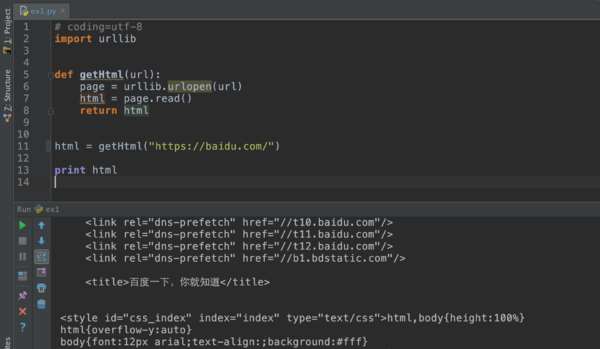
# coding=utf-8
import urllib
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
html = getHtml("https://baidu.com/")
print html
运行效果:
python爬虫什么教程最好
可以看这个教程:网页链接
此教程 通过三个爬虫案例来使学员认识Scrapy框架、了解Scrapy的架构、熟悉Scrapy各模块。
此教程的大致内容:
1、Scrapy的简介。
主要知识点:Scrapy的架构和运作流程。
2、搭建开发环境:
主要知识点:Windows及Linux环境下Scrapy的安装。
3、Scrapy Shell以及Scrapy Selectors的使用。
4、使用Scrapy完成网站信息的爬取。
主要知识点:创建Scrapy项目(scrapy startproject)、定义提取的结构化数据(Item)、编写爬取网站的 Spider 并提取出结构化数据(Item)、编写 Item Pipelines 来存储提取到的Item(即结构化数据)。
data-log="fm:oad,pos:oad-ti,si:3,relv:0,st:2"怎么用python写爬虫来抓数据
Python爬虫可以爬取的东西有很多,Python爬虫怎么学?简单的分析下:
如果你仔细观察,就不难发现,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得简单、容易上手。
利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如:
知乎:爬取优质答案,为你筛选出各话题下最优质的内容。
淘宝、京东:抓取商品、评论及销量数据,对各种商品及用户的消费场景进行分析。
安居客、链家:抓取房产买卖及租售信息,分析房价变化趋势、做不同区域的房价分析。
拉勾网、智联:爬取各类职位信息,分析各行业人才需求情况及薪资水平。
雪球网:抓取雪球高回报用户的行为,对股票市场进行分析和预测。
爬虫是入门Python最好的方式,没有之一。Python有很多应用的方向,比如后台开发、web开发、科学计算等等,但爬虫对于初学者而言更友好,原理简单,几行代码就能实现基本的爬虫,学习的过程更加平滑,你能体会更大的成就感。
掌握基本的爬虫后,你再去学习Python数据分析、web开发甚至机器学习,都会更得心应手。因为这个过程中,Python基本语法、库的使用,以及如何查找文档你都非常熟悉了。
对于小白来说,爬虫可能是一件非常复杂、技术门槛很高的事情。比如有人认为学爬虫必须精通 Python,然后哼哧哼哧系统学习 Python 的每个知识点,很久之后发现仍然爬不了数据;有的人则认为先要掌握网页的知识,遂开始 HTMLCSS,结果入了前端的坑,瘁……
但掌握正确的方法,在短时间内做到能够爬取主流网站的数据,其实非常容易实现,但建议你从一开始就要有一个具体的目标。
在目标的驱动下,你的学习才会更加精准和高效。那些所有你认为必须的前置知识,都是可以在完成目标的过程中学到的。这里给你一条平滑的、零基础快速入门的学习路径。
1.学习 Python 包并实现基本的爬虫过程
2.了解非结构化数据的存储
3.学习scrapy,搭建工程化爬虫
4.学习数据库知识,应对大规模数据存储与提取
5.掌握各种技巧,应对特殊网站的反爬措施
6.分布式爬虫,实现大规模并发采集,提升效率
一
学习 Python 包并实现基本的爬虫过程
大部分爬虫都是按“发送请求――获得页面――解析页面――抽取并储存内容”这样的流程来进行,这其实也是模拟了我们使用浏览器获取网页信息的过程。
Python中爬虫相关的包很多:urllib、requests、bs4、scrapy、pyspider 等,建议从requests+Xpath 开始,requests 负责连接网站,返回网页,Xpath 用于解析网页,便于抽取数据。
如果你用过 BeautifulSoup,会发现 Xpath 要省事不少,一层一层检查元素代码的工作,全都省略了。这样下来基本套路都差不多,一般的静态网站根本不在话下,豆瓣、糗事百科、腾讯新闻等基本上都可以上手了。
当然如果你需要爬取异步加载的网站,可以学习浏览器抓包分析真实请求或者学习Selenium来实现自动化,这样,知乎、时光网、猫途鹰这些动态的网站也可以迎刃而解。
二
了解非结构化数据的存储
爬回来的数据可以直接用文档形式存在本地,也可以存入数据库中。
开始数据量不大的时候,你可以直接通过 Python 的语法或 pandas 的方法将数据存为csv这样的文件。
当然你可能发现爬回来的数据并不是干净的,可能会有缺失、错误等等,你还需要对数据进行清洗,可以学习 pandas 包的基本用法来做数据的预处理,得到更干净的数据。
三
学习 scrapy,搭建工程化的爬虫
掌握前面的技术一般量级的数据和代码基本没有问题了,但是在遇到非常复杂的情况,可能仍然会力不从心,这个时候,强大的 scrapy 框架就非常有用了。
scrapy 是一个功能非常强大的爬虫框架,它不仅能便捷地构建request,还有强大的 selector 能够方便地解析 response,然而它最让人惊喜的还是它超高的性能,让你可以将爬虫工程化、模块化。
学会 scrapy,你可以自己去搭建一些爬虫框架,你就基本具备爬虫工程师的思维了。
四
学习数据库基础,应对大规模数据存储
爬回来的数据量小的时候,你可以用文档的形式来存储,一旦数据量大了,这就有点行不通了。所以掌握一种数据库是必须的,学习目前比较主流的 MongoDB 就OK。
MongoDB 可以方便你去存储一些非结构化的数据,比如各种评论的文本,图片的链接等等。你也可以利用PyMongo,更方便地在Python中操作MongoDB。
因为这里要用到的数据库知识其实非常简单,主要是数据如何入库、如何进行提取,在需要的时候再学习就行。
五
掌握各种技巧,应对特殊网站的反爬措施
当然,爬虫过程中也会经历一些绝望啊,比如被网站封IP、比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。
遇到这些反爬虫的手段,当然还需要一些高级的技巧来应对,常规的比如访问频率控制、使用代理IP池、抓包、验证码的OCR处理等等。
往往网站在高效开发和反爬虫之间会偏向前者,这也为爬虫提供了空间,掌握这些应对反爬虫的技巧,绝大部分的网站已经难不到你了.
六
分布式爬虫,实现大规模并发采集
爬取基本数据已经不是问题了,你的瓶颈会集中到爬取海量数据的效率。这个时候,相信你会很自然地接触到一个很厉害的名字:分布式爬虫。
分布式这个东西,听起来很恐怖,但其实就是利用多线程的原理让多个爬虫同时工作,需要你掌握 Scrapy + MongoDB + Redis 这三种工具。
Scrapy 前面我们说过了,用于做基本的页面爬取,MongoDB 用于存储爬取的数据,Redis 则用来存储要爬取的网页队列,也就是任务队列。
所以有些东西看起来很吓人,但其实分解开来,也不过如此。当你能够写分布式的爬虫的时候,那么你可以去尝试打造一些基本的爬虫架构了,实现一些更加自动化的数据获取。
你看,这一条学习路径下来,你已然可以成为老司机了,非常的顺畅。所以在一开始的时候,尽量不要系统地去啃一些东西,找一个实际的项目(开始可以从豆瓣、小猪这种简单的入手),直接开始就好。
因为爬虫这种技术,既不需要你系统地精通一门语言,也不需要多么高深的数据库技术,高效的姿势就是从实际的项目中去学习这些零散的知识点,你能保证每次学到的都是最需要的那部分。
当然唯一麻烦的是,在具体的问题中,如何找到具体需要的那部分学习资源、如何筛选和甄别,是很多初学者面临的一个大问题。
以上就是我的回答,希望对你有所帮助,望。
Python爬虫可以爬取什么
世界上80%的爬虫是基于Python开发的,学好爬虫技能,可为后续的大数据分析、挖掘、机器学习等提供重要的数据源。
什么是爬虫?
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
其实通俗的讲就是通过程序去获取web页面上自己想要的数据,也就是自动抓取数据
爬虫可以做什么?
你可以用爬虫爬图片,爬取视频等等你想要爬取的数据,只要你能通过浏览器访问的数据都可以通过爬虫获取。
爬虫的本质是什么?
模拟浏览器打开网页,获取网页中我们想要的那部分数据
浏览器打开网页的过程:
当你在浏览器中输入地址后,经过DNS服务器找到服务器主机,向服务器发送一个请求,服务器经过解析后发送给用户浏览器结果,包括html,js,css等文件内容,浏览器解析出来最后呈现给用户在浏览器上看到的结果
所以用户看到的浏览器的结果就是由HTML代码构成的,我们爬虫就是为了获取这些内容,通过分析和过滤html代码,从中获取我们想要资源。
Python爬虫是什么?
打开python爬虫代码的源码目录,通常开始文件为,init.py,start.py,app.py寻找有没有类似的python文件,如果没有,请看源码的readme文件,里面会有说明,若以上都没有,你可能需要python方面的知识,自己去看源码,找到入口方法并运行
找到入口文件后,在当前目录打开控制台,输入python
正常情况下会出现下图的提示,若没有,请检查当前pc的python环境是否有被正确安装

最后,运行入口文件,输入python ***.py(入口文件),运行爬虫
python 爬虫代码 有了爬虫代码怎么运行
爬虫一般是指网络资源的抓取,因为python的脚本特性,python易于配置,对字符的处理也非常灵活,加上python有丰富的网络抓取模块,所以两者经常联系在一起。
python爬虫可以用来做什么
1、通过Headers反爬虫:
从用户请求的Headers反爬虫是最常见的反爬虫策略。可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。
2、基于用户行为反爬虫:
直接使用芝麻IP代理就可以解决。
python爬虫中怎么写反爬虫
1)在校大学生。最好是数学或计算机相关专业,编程能力还可以的话,稍微看一下爬虫知识,主要涉及一门语言的爬虫库、html解析、内容存储等,复杂的还需要了解URL排重、模拟登录、验证码识别、多线程、代理、移动端抓取等。由于在校学生的工程经验比较少,建议只接一些少量数据抓取的项目,而不要去接一些监控类的项目、或大规模抓取的项目。慢慢来,步子不要迈太大。
(2)在职人员。如果你本身就是爬虫工程师,接私活很简单。如果你不是,也不要紧。只要是做IT的,稍微学习一下爬虫应该不难。在职人员的优势是熟悉项目开发流程,工程经验丰富,能对一个任务的难度、时间、花费进行合理评估。可以尝试去接一些大规模抓取任务、监控任务、移动端模拟登录并抓取任务等,收益想对可观一些。
渠道:淘宝、熟人介绍、猪八戒、csdn、发源地、QQ群等!
扩展资料:
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。搜索引擎(Search Engine),例如传统的通用搜索引擎AltaVista,Yahoo!和Google等,作为一个辅助人们检索信息的工具成为用户访问万维网的入口和指南。但是,这些通用性搜索引擎也存在着一定的局限性,如:
(1)不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。
(2)通用搜索引擎的目标是尽可能大的网络覆盖率,有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。
(3)万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎往往对这些信息含量密集且具有一定结构的数据无能为力,不能很好地发现和获取。
(4)通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询。
为了解决上述问题,定向抓取相关网页资源的聚焦爬虫应运而生。聚焦爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。与通用爬虫(general purpose web crawler)不同,聚焦爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
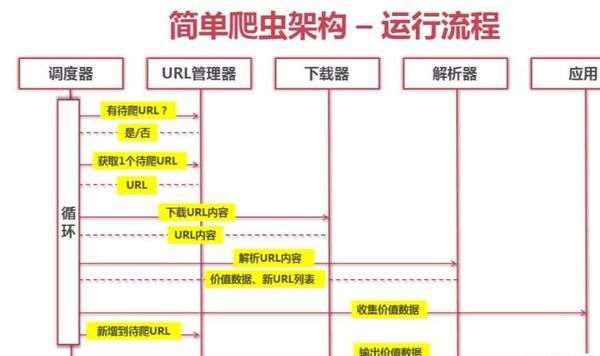
1 聚焦爬虫工作原理以及关键技术概述
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:
(1) 对抓取目标的描述或定义;
(2) 对网页或数据的分析与过滤;
(3) 对URL的搜索策略。
热门曲谱
 刘德华喊话四大天王合体做节目:他们愿意我 彭于晏带违规水果过海关被罚 据台湾媒体报道,彭于晏7月1日返回台北在松山机场过海关的时候,因为不小心带了水果,被海关查获并罚款3000元台币 。有台湾媒体询问机场工作人...[详情]分类:知识库时间:12:37
刘德华喊话四大天王合体做节目:他们愿意我 彭于晏带违规水果过海关被罚 据台湾媒体报道,彭于晏7月1日返回台北在松山机场过海关的时候,因为不小心带了水果,被海关查获并罚款3000元台币 。有台湾媒体询问机场工作人...[详情]分类:知识库时间:12:37 led和节能灯哪个好
led和节能灯哪个好 概括:这道题是贲友颗同学的课后练习题,主要是关于led和节能灯哪个好,指导老师为黎老师。LED节能灯是继紧凑型荧光灯(即普通节能灯...
[详情]分类:知识库时间:14:47 个人所得税税率
个人所得税税率 概括:这道题是蒲值暇同学的课后练习题,主要是关于个人所得税税率,指导老师为阚老师。
题目:个人所得税税率
解:<...[详情]分类:知识库时间:14:51 个税计算方法
个税计算方法 概括:这道题是文缘卣同学的课后练习题,主要是关于个税计算方法,指导老师为惠老师。负所得税制度的意义财税部门出台了给予弱势群...
[详情]分类:知识库时间:14:51 李光洁宣布结婚 彭于晏带违规水果过海关被罚 据台湾媒体报道,彭于晏7月1日返回台北在松山机场过海关的时候,因为不小心带了水果,被海关查获并罚款3000元台币 。有台湾媒体询问机场工作人...[详情]分类:知识库时间:12:37
李光洁宣布结婚 彭于晏带违规水果过海关被罚 据台湾媒体报道,彭于晏7月1日返回台北在松山机场过海关的时候,因为不小心带了水果,被海关查获并罚款3000元台币 。有台湾媒体询问机场工作人...[详情]分类:知识库时间:12:37 什么可以美白牙齿
什么可以美白牙齿 概括:这道题是贡泼俊同学的课后练习题,主要是关于什么可以美白牙齿,指导老师为井老师。冷光美白牙齿顾名思义就是用冷光来美白牙...
[详情]分类:知识库时间:14:58 什么是连带责任
什么是连带责任 概括:这道题是满澄檬同学的课后政治练习题,主要是关于什么是连带责任,指导老师为宦老师。
题目:什么是连带责任
...[详情]分类:知识库时间:14:58 趣头条与江苏卫视达成战略合作 彭于晏带违规水果过海关被罚 据台湾媒体报道,彭于晏7月1日返回台北在松山机场过海关的时候,因为不小心带了水果,被海关查获并罚款3000元台币 。有台湾媒体询问机场工作人...[详情]分类:知识库时间:12:37
趣头条与江苏卫视达成战略合作 彭于晏带违规水果过海关被罚 据台湾媒体报道,彭于晏7月1日返回台北在松山机场过海关的时候,因为不小心带了水果,被海关查获并罚款3000元台币 。有台湾媒体询问机场工作人...[详情]分类:知识库时间:12:37 利率怎么算
利率怎么算 概括:这道题是从纲凑同学的课后练习题,主要是关于利率怎么算,指导老师为殳老师。银行利率表示一定时期内利息量与本金的比率,通...
[详情]分类:知识库时间:14:58 名贵树种
名贵树种 概括:这道题是山翁灿同学的课后练习题,主要是关于名贵树种,指导老师为谈老师。
题目:名贵树种
解: ...[详情]分类:知识库时间:14:56 埃利斯
埃利斯 概括:这道题是苏似涡同学的课后政治练习题,主要是关于埃利斯,指导老师为裴老师。
题目:埃利斯
解: ...[详情]分类:知识库时间:14:54 差异
差异 概括:这道题是巫唐抖同学的课后练习题,主要是关于差异,指导老师为左老师。暂时性差异是由税收法规与会计准则确认时间或计税基础...
[详情]分类:知识库时间:14:53 平衡梁
平衡梁 概括:这道题是浦晓淖同学的课后练习题,主要是关于平衡梁,指导老师为赵老师。平衡梁为吊装机具的重要组成部分,可用于保持被吊设...
[详情]分类:知识库时间:14:54 建筑图集
建筑图集 概括:这道题是蓟侠位同学的课后政治练习题,主要是关于建筑图集,指导老师为焦老师。《新疆传统建筑图集》是2009年新疆科学技术出...
[详情]分类:知识库时间:14:54 成分分析
成分分析 概括:这道题是颜仑徽同学的课后练习题,主要是关于成分分析,指导老师为戈老师。
题目:成分分析
解: ...[详情]分类:知识库时间:14:56 无坚不摧之力
无坚不摧之力 概括:这道题是路婆掖同学的课后政治练习题,主要是关于无坚不摧之力,指导老师为祁老师。
题目:无坚不摧之力
解:<...[详情]分类:知识库时间:14:54 气垫船原理
气垫船原理 概括:这道题是席洞朴同学的课后练习题,主要是关于气垫船原理,指导老师为毛老师。通风工程是送风、排风、除尘、气力输送以及防、...
[详情]分类:知识库时间:14:54 海狸
海狸 概括:这道题是项筛卦同学的课后练习题,主要是关于海狸,指导老师为钱老师。
题目:海狸
解: ...[详情]分类:知识库时间:14:56 38译码器
38译码器 知识点:《38译码器》 收集:瞿收霉 编辑:桂花
[详情]分类:知识库时间:10:57
本知识点包括:1、38译码器在单片机系统中的作用是什么? 2、求vh... aidma
aidma 知识点:《aidma》 收集:蒯超峦 编辑:栀子花女孩
[详情]分类:知识库时间:12:08
本知识点包括:1、SOV/SOM是什么?AIDMA和AIDAS理论代表什么...