spss数据分析教程
曲谱自学网今天精心准备的是《spss数据分析教程》,下面是详解!
跪求 spss统计分析从零开始学 PDF版本
spss统计分析从零开始学PDF...
spss统计分析从零开始学PDF
楼主可直接下载附件,spss19经典教程,我就是根据这个入门的
怎么用spss分析数据?
我在做一个关于影响中学生环保意识水平的调查报告,设计的影响因素有15项,想从中找出影响最大的一组因素,应该怎么操作?谢谢...
我在做一个关于影响中学生环保意识水平的调查报告,设计的影响因素有15项,想从中找出影响最大的一组因素,应该怎么操作?谢谢
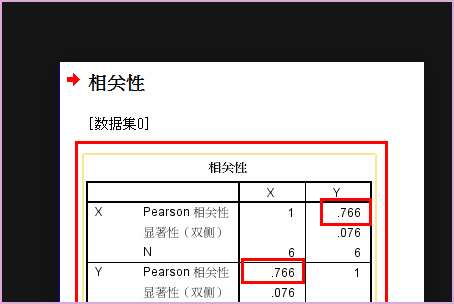
1、选取在理论上有一定关系的两个变量,如用X,Y表示,数据输入到SPSS中。
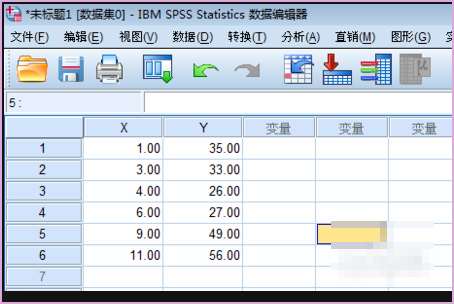
2、从总体上来看、X和Y的趋势有一定的一致性。
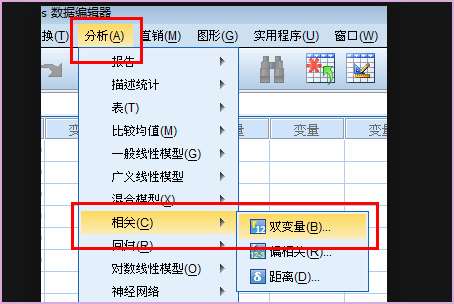
3、为了解决相似性强弱用SPSS进行分析、从分析-相关-双变量。
4、打开双变量相关对话框,将X和Y选中导入到变量窗口。
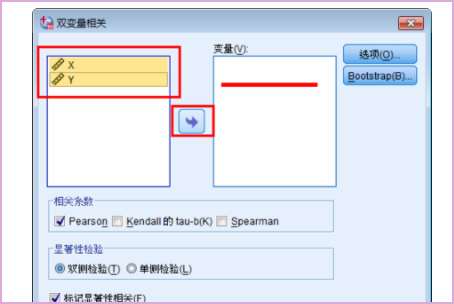
5、然后相关系数选择Pearson相关系数,也可以选择其他两个。
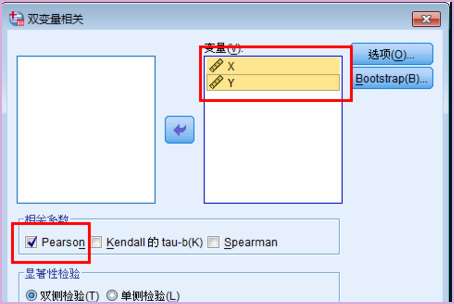
6、点击确定在结果输出窗口显示相关性分析结果。
如何用spss 做卡方检验
手头做一个研究数据如下发病人数未发病人数甲组2624乙组2921求用spss17.0做如何录入数据,做卡方检验~谢谢咳咳,我用的是汉化版本,英语不好啊,,,看不懂....求大神给翻译下吧~...
手头做一个研究 数据如下
发病人数 未发病人数
甲组 26 24
乙组 29 21
求用spss17.0 做如何录入数据,做卡方检验~ 谢谢
咳咳,我用的是汉化版本,英语不好啊,,,看不懂....求大神给翻译下吧~
1、建立数据文件。对新手而言此步最关键。
打开软件,“新数据集”, 假如是一个两列三行的数据,在Excel中原始表可以是两列并立,共3行数字,而此时在SPSS中新数据集建成后则一般为单列6行数字。
在变量视图中设置变量为第一步,假如在Excel中是一个两列三行的数据,在Excel中两列题头分别为“不突出子宫”“突出子宫”,在Excel中三行分别为“粘连型”“植入型”“穿透型”,则在SPSS中需设置3个变量,第一变量名称填为“位置”,类型选“字符串”,测量选“名义”; 第二变量名称填为“类型”,类型选“字符串”,测量选“名义”; 第三变量名称填为“数值”,类型选“数值”,测量选“度量”;

(图1)
在数据视图中开始输入数据,在第一列位置下第1、2行分别输入“不突出”“突出”,第3、4行;5、6行同1、2行;在第二列类型下第1、2行输入“粘连型”,3、4行输入“ 植入型”,5、6行输入“ 穿透型”;在第三列数值下输入各类数据的具体值。
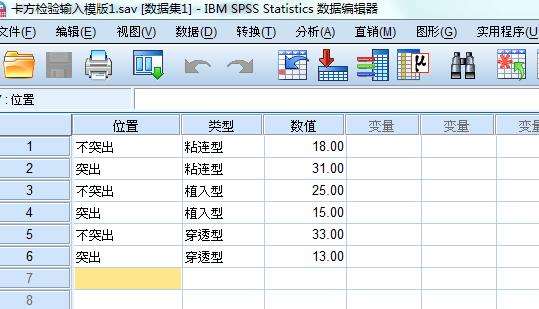
至此,数据集建立完毕。
2、单击主菜单“数据"-”加权个案“,打开加权个案对话框。从左边源变量选择“数值”作为权变量,将其选入“频率变量:”框中,单击”确定“按钮,执行加权命令。
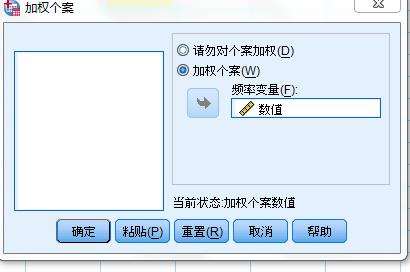
加权后此行数值作为个数出现,如35表示有35例;而不加权则此行数值作为单一数值,如35cm之类。
3、单击主菜单中的“分析”-“描述统计”-“交叉表”,打开对话框。
将左边源对话框中的“位置”作为行变量调入“行:”下的矩形框;“类型”作为列变量调入“列:”下矩形框。
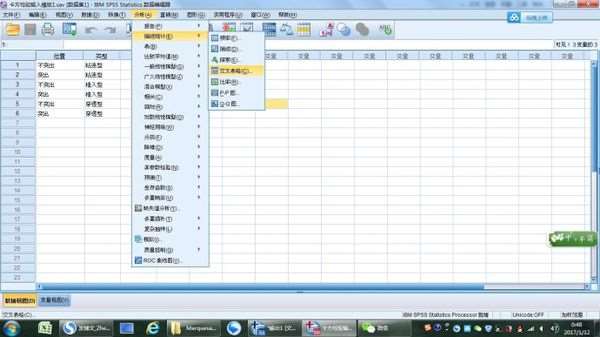
4、单击“交叉表”对话框中的“统计量”选项,选中“卡方”,单击“继续”,返回到“交叉表”对话框。
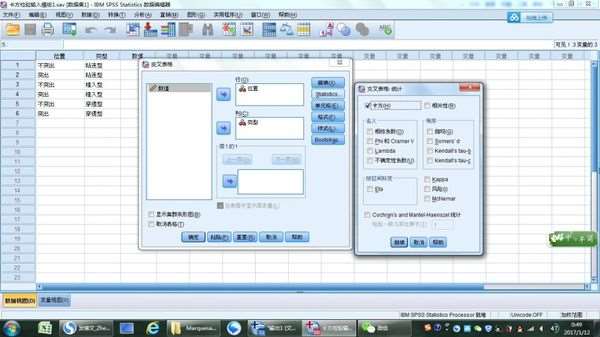
5、单击"单元格"选项,在计数下激活“期望值”,在百分比下激活“行”,单击“继续”,返回到“交叉表”对话框。
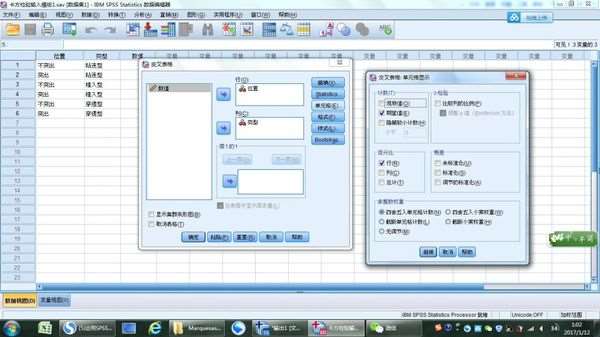
6、在“交叉表”对话框中,单击"确定"按钮,即可得输出结果。
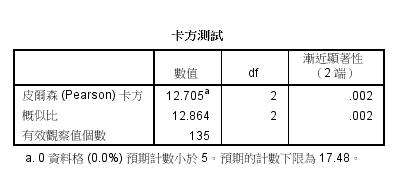
7、卡方检验结果:主要看pearson卡方检验行,pearson卡方数值即为卡方值(如下的12.705),渐近显著性(sig)值即为P值(如下的0.002),小于0.05时认为不同位置对不同类型的胎盘判断有显著的差别。
扩展资料:
SPSS(Statistical Product and Service Solutions),“统计产品与服务解决方案”软件。最初软件全称为“社会科学统计软件包”(SolutionsStatistical Package for the Social Sciences),但是随着SPSS产品服务领域的扩大和服务深度的增加,SPSS公司已于2000年正式将英文全称更改为“统计产品与服务解决方案”,这标志着SPSS的战略方向正在做出重大调整。
SPSS为IBM公司推出的一系列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称,有Windows和Mac OS X等版本。
1984年SPSS总部首先推出了世界上第一个统计分析软件微机版本SPSS/PC+,开创了SPSS微机系列产品的开发方向,极大地扩充了它的应用范围,并使其能很快地应用于自然科学、技术科学、社会科学的各个领域。世界上许多有影响的报刊杂志纷纷就SPSS的自动统计绘图、数据的深入分析、使用方便、功能齐全等方面给予了高度的评价。
参考资料:百度百科-spss
怎样用SPSS检验数据显著性?
样品有8个,每个样品分别用两种指示剂滴定,一个样品一种指示剂做4次重复,数据如下。用SPSS的哪种方法检验,能得出哪种指示剂的测的更准确?需要每个样品检验一次,还是可以8个样品一...
样品有8个,每个样品分别用两种指示剂滴定,一个样品一种指示剂做4次重复,数据如下。用SPSS的哪种方法检验,能得出哪种指示剂的测的更准确?需要每个样品检验一次,还是可以8个样品一起检验?求大神指教! 展开
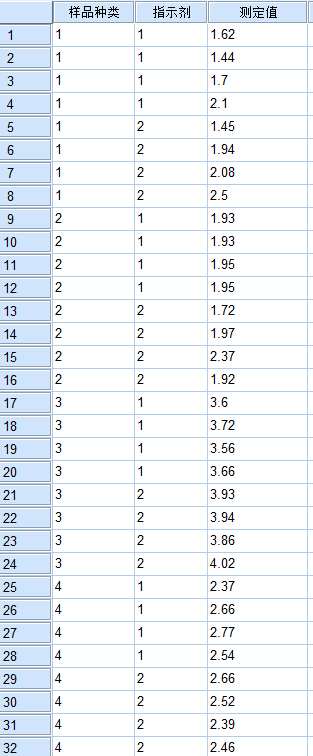
1,数据输入方式不当。应设变量1为种类(有8个种类,1,2,...8),变量2为指示剂(有2种检测方法,1, 2)。
正确的数据表应为两变量的组合(如1,1;2,1;3,1,,,,),再加上测定值的三列表格。
注意是4次重复,所以组合也要重复4次。
2,采用单变量方差分析。分析--一般线性模型--单变量。选测定值为因变量,种类和指示剂为固定因子。按需要选择两两比较的方法。确定即可。
3,无法得出哪种指示剂测定的更准确,只能得出两种指示剂测定的结果是否有差异,是否相同。
4,两两比较页面,选入固子种类,再选择两两比较的方法,如Duncan比较方法。一次检验结果是可以一起分析8种类样品之间的差异的。
扩展
很详细呢,但是我是新手,所以还是有的地方不明白。。测定值每个样品用两种指示剂所以都有两组,怎么是三列表格?如果两种试剂的测定值都放在一列里,要怎么区分呢?还有,重复四次,是在这三列的下边重复吗,我的意思是,前边是1-8,然后接着9-16重复,这样吗?谢谢!
补充
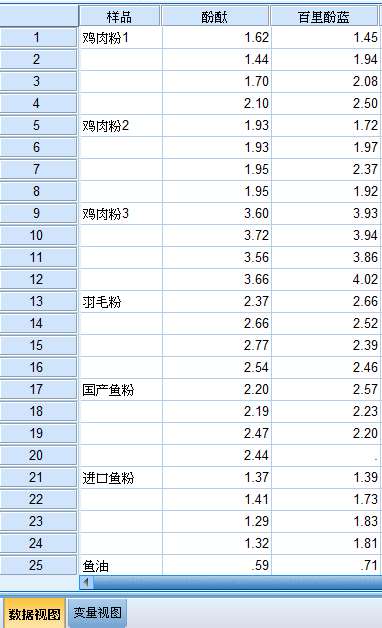
因数据不全,下表为前4个样品种类*2种指示剂所形成的表格。
样品种类的1,2,3,4就分别代表鸡肉粉1,鸡肉粉2,鸡肉粉3,羽毛粉。
指示剂1,2分别代表酚酞和百里酚蓝。当然数字是可以定义为具体名称的,不会影响分析结果。
如组合(1 *1)就出现了四次,代表着四次重复,而测定值各不相同,但只有1列。
所以总共就3列。

怎么使用SPSS软件
怎么使用SPSS软件...
怎么使用SPSS软件
当我们的调查问卷在把调查数据拿回来后,我们该做的工作就是用相关的统计软件进行处理,在此,我们以spss为处理软件,来简要说明一下问卷的处理过程,它的过程大致可分为四个过程:定义变量、数据录入、统计分析和结果保存.下面将从这四个方面来对问卷的处理做详细的介绍.
Spss处理:
第一步:定义变量
大多数情况下我们需要从头定义变量,在打开SPSS后,我们可以看到和excel相似的界面,在界面的左下方可以看到Data View, Variable View两个标签,只需单击左下方的Variable View标签就可以切换到变量定义界面开始定义新变量。在表格上方可以看到一个变量要设置如下几项:name(变量名)、type(变量类型)、width(变量值的宽度)、decimals(小数位) 、label(变量标签) 、Values(定义具体变量值的标签)、Missing(定义变量缺失值)、Colomns(定义显示列宽)、Align(定义显示对齐方式)、Measure(定义变量类型是连续、有序分类还是无序分类).
我们知道在spss中,我们可以把一份问卷上面的每一个问题设为一个变量,这样一份问卷有多少个问题就要有多少个变量与之对应,每一个问题的答案即为变量的取值.现在我们以问卷第一个问题为例来说明变量的设置.为了便于说明,可假设此题为:
1.请问你的年龄属于下面哪一个年龄段( )?
A:20―29 B:30―39 C:40―49 D:50--59
那么我们的变量设置可如下: name即变量名为1,type即类型可根据答案的类型设置,答案我们可以用1、2、3、4来代替A、B、C、D,所以我们选择数字型的,即选择Numeric, width宽度为4,decimals即小数位数位为0(因为答案没有小数点),label即变量标签为“年龄段查询”。Values用于定义具体变量值的标签,单击Value框右半部的省略号,会弹出变量值标签对话框,在第一个文本框里输入1,第二个输入20―29,然后单击添加即可.同样道理我们可做如下设置,即1=20―29、2=30―39、3=40―49、4=50--59;Missing,用于定义变量缺失值, 单击missing框右侧的省略号,会弹出缺失值对话框, 界面上有一列三个单选钮,默认值为最上方的“无缺失值”;第二项为“不连续缺失值”,最多可以定义3个值;最后一项为“缺失值范围加可选的一个缺失值”,在此我们不设置缺省值,所以选中第一项如图;Colomns,定义显示列宽,可自己根据实际情况设置;Align,定义显示对齐方式,有居左、居右、居中三种方式;Measure,定义变量类型是连续、有序分类还是无序分类。
以上为问卷中常见的单项选择题型的变量设置,下面将对一些特殊情况的变量设置也作一下说明.
1.开放式题型的设置:诸如你所在的省份是_____这样的填空题即为开放题,设置这些变量的时候只需要将Value 、Missing两项不设置即可.
2.多选题的变量设置:这类题型的设置有两种方法即多重二分法和多重分类法,在这里我们只对多重二分法进行介绍.这种方法的基本思想是把该题每一个选项设置成一个变量,然后将每一个选项拆分为两个选项项,即选中该项和不选中该项.现在举例来说明在spss中的具体操作.比如如下一例:
请问您通常获取新闻的方式有哪些( )
1 报纸 2 杂志 3 电视 4 收音机 5 网络
在spss中设置变量时可为此题设置五个变量,假如此题为问卷第三题,那么变量名分别为3_1、3_2、3_3、3_4、3_5,然后每一个选项有两个选项选中和不选中,只需在Value一项中为每一个变量设置成1=选中此项、0=不选中此项即可.
使用该窗口,我们可以把一个问卷中的所有问题作为变量在这个窗口中一次定义。
到此,我们的定义变量的工作就基本上可以结束了.下面我们要作就是数据的录入了.首先,我们要回到数据录入窗口,这很简单,只要我们点击软件左下方的Data View标签就可以了.
第二步:数据录入
Spss数据录入有很多方式,大致有一下几种:
1.读取SPSS格式的数据
2.读取Excel等格式的数据
3.读取文本数据(Fixed和Delimiter)
4.读取数据库格式数据(分如下两步)
(1)配置ODBC (2)在SPSS中通过ODBC和数据库进行
但是对于问卷的数据录入其实很简单,只要在spss的数据录入窗口中直接输入就可以了,只是在这里有几点注意的事项需要说明一下.
1. 在数据录入窗口,我们可以看到有一个表格,这个表格中的每一行代表一份问卷,我们也称为一个个案.
2. 在数据录入窗口中,我们可以看到表格上方出现了1、2、3、4、5…….的标签名,这其实是我们在第一步定义变量中,我们为问卷的每一个问题取的变量名,即1代表第一题,2代表第二题.以次类推.我们只需要在变量名下面输入对应问题的答案即可完成问卷的数据录入.比如上述年龄段查询的例题,如果问卷上勾选了A答案,我们在1下面输入1就行了(不要忘记我们通常是用1、2、3、4来代替A、B、C、D的).
3.我们知道一行代表一份问卷,所以有几分问卷,就要有几行的数据.
在数据录入完成后,我们要做的就是我们的关键部分,即问卷的统计分析了,因为这时我们已经把问卷中的数据录入我们的软件中了.
第三步:统计分析
有了数据,可以利用SPSS的各种分析方法进行分析,但选择何种统计分析方法,即调用哪个统计分析过程,是得到正确分析结果的关键。这要根据我们的问卷调查的目的和我们想要什么样的结果来选择.SPSS有数值分析和作图分析两类方法.
1.作图分析:
在SPSS中,除了生存分析所用的生存曲线图被整合到Analyze菜单中外,其他的统计绘图功能均放置在graph菜单中。该菜单具体分为以下几部分::
(1)Gallery:相当于一个自学向导,将统计绘图功能做了简单的介绍,初学者可以通过它对SPSS的绘图能力有一个大致的了解。
(2)Interactive:交互式统计图。
(3)Map:统计地图。
(4)下方的其他菜单项是我们最为常用的普通统计图,具体来说有:
条图
散点图
线图
直方图
饼图
面积图
箱式图
正态Q-Q图
正态P-P图
质量控制图
Pareto图
自回归曲线图
高低图
交互相关图
序列图
频谱图
误差线图
作图分析简单易懂,一目了然,我们可根据需要来选择我们需要作的图形,一般来讲,我们较常用的有条图,直方图,正态图,散点图,饼图等等,具体操作很简单,大家可参阅相关书籍,作图分析更多情况下是和数值分析相结合来对试卷进行分析的,这样的效果更好.
2.数值分析:
SPSS 数值统计分析过程均在Analyze菜单中,包括:
(1)、Reports和Descriptive Statistics:又称为基本统计分析.基本统计分析是进行其他更深入的统计分析的前提,通过基本统计分析,用户可以对分析数据的总体特征有比较准确的把握,从而选择更为深入的分析方法对分析对象进行研究。Reports和Descriptive Statistics命令项中包括的功能是对单变量的描述统计分析。
Descriptive Statistics包括的统计功能有:
Frequencies(频数分析):作用:了解变量的取值分布情况
Descriptives(描述统计量分析):功能:了解数据的基本统计特征和对指定的变量值进行标准化处理
Explore(探索分析):功能:考察数据的奇异性和分布特征
Crosstabs(交叉分析):功能:分析事物(变量)之间的相互影响和关系
Reports包括的统计功能有:
OLAP Cubes(OLAP报告摘要表):功能: 以分组变量为基础,计算各组的总计、均值和其他统计量。而输出的报告摘要则是指每个组中所包含的各种变量的统计信息。
Case Summaries(观测量列表):察看或打印所需要的变量值
Report Summaries in Row:行形式输出报告
Report Summaries in Columns:列形式输出报告
(2)、Compare Means(均值比较与检验):能否用样本均值估计总体均值?两个变量均值接近的样本是否来自均值相同的总体?换句话说,两组样本某变量均值不同,其差异是否具有统计意义?能否说明总体差异?这是各种研究工作中经常提出的问题。这就要进行均值比较。
以下是进行均值比较及检验的过程:
MEANS过程:不同水平下(不同组)的描述统计量,如男女的平均工资,各工种的平均工资。目的在于比较。术语:水平数(指分类变量的值数,如sex变量有2个值,称为有两个水平)、单元Cell(指因变量按分类变量值所分的组)、水平组合
T test 过程:对样本进行T检验的过程
单一样本的T检验:检验单个变量的均值是否与给定的常数之间存在差异。
独立样本的T检验:检验两组不相关的样本是否来自具有相同均值的总体(均值是否相同,如男女的平均收入是否相同,是否有显著性差异)
配对T检验:检验两组相关的样本是否来自具有相同均值的总体(前后比较,如训练效果,治疗效果)
One-Way ANOVA:一元(单因素)方差分析,用于检验几个(三个或三个以上)独立的组,是否来自均值相同的总体。
(3)、ANOVA Models(方差分析):方差分析是检验多组样本均值间的差异是否具有统计意义的一种方法。例如:医学界研究几种药物对某种疾病的疗效;农业研究土壤、肥料、日照时间等因素对某种农作物产量的影响;不同饲料对牲畜体重增长的效果等,都可以使用方差分析方法去解决
(4)、Correlate(相关分析):它是研究变量间密切程度的一种常用统计方法,常用的相关分析有以下几种:
1、线性相关分析:研究两个变量间线性关系的程度。用相关系数r来描述。
2、偏相关分析:它描述的是当控制了一个或几个另外的变量的影响条件下两个变量间的相关性,如控制年龄和工作经验的影响,估计工资收入与受教育水平之间的相关关系
3、相似性测度:两个或若干个变量、两个或两组观测量之间的关系有时也可以用相似性或不相似性来描述。相似性测度用大值表示很相似,而不相似性用距离或不相似性来描述,大值表示相差甚远
(5)、Regression(回归分析):功能:寻求有关联(相关)的变量之间的关系在回归过程中包括:Liner:线性回归;Curve Estimation:曲线估计;Binary Logistic: 二分变量逻辑回归;Multinomial Logistic:多分变量逻辑回归;Ordinal 序回归;Probit:概率单位回归;Nonlinear:非线性回归;Weight Estimation:加权估计;2-Stage Least squares:二段最小平方法;Optimal Scaling 最优编码回归;其中最常用的为前面三个.
(6)、Nonparametric Tests(非参数检验):是指在总体不服从正态分布且分布情况不明时,用来检验数据资料是否来自同一个总体假设的一类检验方法。由于这些方法一般不涉及总体参数故得名。
非参数检验的过程有以下几个:
1.Chi-Square test 卡方检验
2.Binomial test 二项分布检验
3.Runs test 游程检验
4.1-Sample Kolmogorov-Smirnov test 一个样本柯尔莫哥洛夫-斯米诺夫检验
5.2 independent Samples Test 两个独立样本检验
6.K independent Samples Test K个独立样本检验
7.2 related Samples Test 两个相关样本检验
8.K related Samples Test 两个相关样本检验
(7)、Data Reduction(因子分析)
(8)、Classify(聚类与判别)等等
以上就是数值统计分析Analyze菜单下几项用于分析的数值统计分析方法的简介,在我们的变量定义以及数据录入完成后,我们就可以根据我们的需要在以上几种分析方法中选择若干种对我们的问卷数据进行统计分析,来得到我们想要的结果.
第四步:结果保存
我们的spss软件会把我们统计分析的多有结果保存在一个窗口中即结果输出窗口(output),由于spss软件支持复制和粘贴功能,这样我们就可以把我们想要的结果复制、粘贴到我们的报告中,当然我们也可以在菜单中执行file->save来保存我们的结果,一般情况下,我们建议保存我们的数据,结果可不保存.因为只要有了数据,如果我们想要结果的,我们可以随时利用数据得到结果.
总结:
以上便是spss处理问卷的四个步骤,四个步骤结束后,我们需要spss软件做的工作基本上也就结束了,接下来的任务就是写我们的统计报告了.值得一提的是.spss是一款在社会统计学应用非常广泛的统计类软件,学好它将对我们以后的工作学习产生很大的意义和作用.
如何用SPSS对数据进行标准化处理
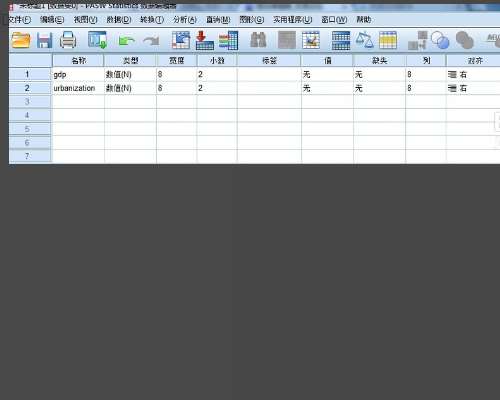
1、打开spss,将界面切换到变量视图。在编辑栏目创建观测指标及类型。示例创建两个指标,一个作为自变量,另外一个作为因变量,分别是gpd和urbanization,代表人均gdp和城市化水平。
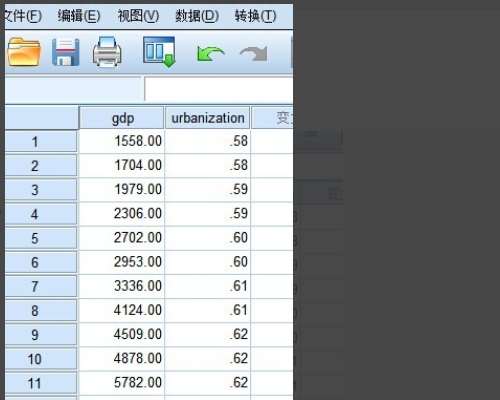
2、指标及类型建好了以后,就要输入数据到spss中了。切换到“数据视图”,数据可以手工输入,也可以从excel中复制或导入。
3、分析--》回归,对数据进行线性回归分析。
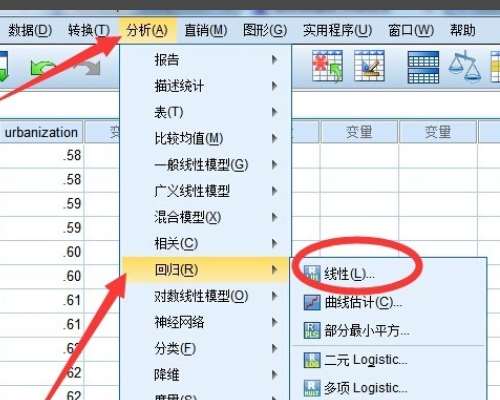
4、进入线性回归详细设置界面,设置自变量,因变量。
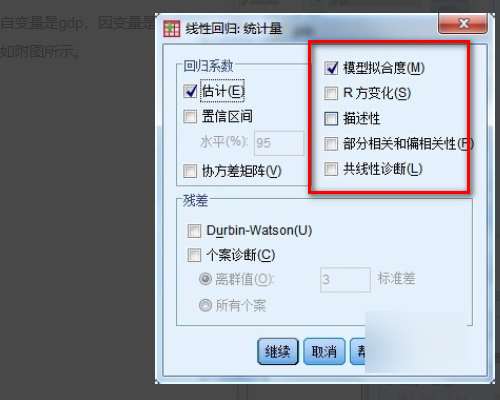
5、设置好各项参数后,点击确定,spss就会按照预设进行分析并自动输出分析的结果。分析结果如附图所示,由分析结果已知,自变量与因变量符合线性回归模型。
用spss22怎么做数据分析
说集体点,刚用Spss处理完一个调查问卷的项目,我相信肯定能帮到你!
1、如果你的数据是excel文件,直接导入到spss中(文件-数据-》选择你的数据文件)
2、其他格式的也可以导入,如果没有数据,你自己在spss里面输入,和excel没什么不同
3、因子分析,检验数据的效度,提取因子
4、信度分析
5、回归分析,计算出路径系数,这也就是最后需要的结果。
希望能帮到到您!
spss数据分析培训班哪个好?
都可以啊,看个人情况。自学的话花费的时间比较多,自学能力强的同学可以选择。培训的话比较快,也可以拿证书。但是需要花钱,相当于花钱买时间和经验。
热门曲谱
 刘德华喊话四大天王合体做节目:他们愿意我 彭于晏带违规水果过海关被罚 据台湾媒体报道,彭于晏7月1日返回台北在松山机场过海关的时候,因为不小心带了水果,被海关查获并罚款3000元台币 。有台湾媒体询问机场工作人...[详情]分类:知识库时间:12:37
刘德华喊话四大天王合体做节目:他们愿意我 彭于晏带违规水果过海关被罚 据台湾媒体报道,彭于晏7月1日返回台北在松山机场过海关的时候,因为不小心带了水果,被海关查获并罚款3000元台币 。有台湾媒体询问机场工作人...[详情]分类:知识库时间:12:37 led和节能灯哪个好
led和节能灯哪个好 概括:这道题是贲友颗同学的课后练习题,主要是关于led和节能灯哪个好,指导老师为黎老师。LED节能灯是继紧凑型荧光灯(即普通节能灯...
[详情]分类:知识库时间:14:47 个人所得税税率
个人所得税税率 概括:这道题是蒲值暇同学的课后练习题,主要是关于个人所得税税率,指导老师为阚老师。
题目:个人所得税税率
解:<...[详情]分类:知识库时间:14:51 个税计算方法
个税计算方法 概括:这道题是文缘卣同学的课后练习题,主要是关于个税计算方法,指导老师为惠老师。负所得税制度的意义财税部门出台了给予弱势群...
[详情]分类:知识库时间:14:51 李光洁宣布结婚 彭于晏带违规水果过海关被罚 据台湾媒体报道,彭于晏7月1日返回台北在松山机场过海关的时候,因为不小心带了水果,被海关查获并罚款3000元台币 。有台湾媒体询问机场工作人...[详情]分类:知识库时间:12:37
李光洁宣布结婚 彭于晏带违规水果过海关被罚 据台湾媒体报道,彭于晏7月1日返回台北在松山机场过海关的时候,因为不小心带了水果,被海关查获并罚款3000元台币 。有台湾媒体询问机场工作人...[详情]分类:知识库时间:12:37 什么可以美白牙齿
什么可以美白牙齿 概括:这道题是贡泼俊同学的课后练习题,主要是关于什么可以美白牙齿,指导老师为井老师。冷光美白牙齿顾名思义就是用冷光来美白牙...
[详情]分类:知识库时间:14:58 什么是连带责任
什么是连带责任 概括:这道题是满澄檬同学的课后政治练习题,主要是关于什么是连带责任,指导老师为宦老师。
题目:什么是连带责任
...[详情]分类:知识库时间:14:58 趣头条与江苏卫视达成战略合作 彭于晏带违规水果过海关被罚 据台湾媒体报道,彭于晏7月1日返回台北在松山机场过海关的时候,因为不小心带了水果,被海关查获并罚款3000元台币 。有台湾媒体询问机场工作人...[详情]分类:知识库时间:12:37
趣头条与江苏卫视达成战略合作 彭于晏带违规水果过海关被罚 据台湾媒体报道,彭于晏7月1日返回台北在松山机场过海关的时候,因为不小心带了水果,被海关查获并罚款3000元台币 。有台湾媒体询问机场工作人...[详情]分类:知识库时间:12:37 利率怎么算
利率怎么算 概括:这道题是从纲凑同学的课后练习题,主要是关于利率怎么算,指导老师为殳老师。银行利率表示一定时期内利息量与本金的比率,通...
[详情]分类:知识库时间:14:58 名贵树种
名贵树种 概括:这道题是山翁灿同学的课后练习题,主要是关于名贵树种,指导老师为谈老师。
题目:名贵树种
解: ...[详情]分类:知识库时间:14:56 埃利斯
埃利斯 概括:这道题是苏似涡同学的课后政治练习题,主要是关于埃利斯,指导老师为裴老师。
题目:埃利斯
解: ...[详情]分类:知识库时间:14:54 差异
差异 概括:这道题是巫唐抖同学的课后练习题,主要是关于差异,指导老师为左老师。暂时性差异是由税收法规与会计准则确认时间或计税基础...
[详情]分类:知识库时间:14:53 平衡梁
平衡梁 概括:这道题是浦晓淖同学的课后练习题,主要是关于平衡梁,指导老师为赵老师。平衡梁为吊装机具的重要组成部分,可用于保持被吊设...
[详情]分类:知识库时间:14:54 建筑图集
建筑图集 概括:这道题是蓟侠位同学的课后政治练习题,主要是关于建筑图集,指导老师为焦老师。《新疆传统建筑图集》是2009年新疆科学技术出...
[详情]分类:知识库时间:14:54 成分分析
成分分析 概括:这道题是颜仑徽同学的课后练习题,主要是关于成分分析,指导老师为戈老师。
题目:成分分析
解: ...[详情]分类:知识库时间:14:56 无坚不摧之力
无坚不摧之力 概括:这道题是路婆掖同学的课后政治练习题,主要是关于无坚不摧之力,指导老师为祁老师。
题目:无坚不摧之力
解:<...[详情]分类:知识库时间:14:54 气垫船原理
气垫船原理 概括:这道题是席洞朴同学的课后练习题,主要是关于气垫船原理,指导老师为毛老师。通风工程是送风、排风、除尘、气力输送以及防、...
[详情]分类:知识库时间:14:54 海狸
海狸 概括:这道题是项筛卦同学的课后练习题,主要是关于海狸,指导老师为钱老师。
题目:海狸
解: ...[详情]分类:知识库时间:14:56 38译码器
38译码器 知识点:《38译码器》 收集:瞿收霉 编辑:桂花
[详情]分类:知识库时间:10:57
本知识点包括:1、38译码器在单片机系统中的作用是什么? 2、求vh... aidma
aidma 知识点:《aidma》 收集:蒯超峦 编辑:栀子花女孩
[详情]分类:知识库时间:12:08
本知识点包括:1、SOV/SOM是什么?AIDMA和AIDAS理论代表什么...